功夫交易系统架构篇之二 「易筋经初探」

功夫开源版 上线后,得到很多朋友的关注,其中不少人关心内存数据库易筋经的架构设计。的确,做为功夫架构中最核心的精华,易筋经的设计并不那么直观的容易理解,我就在本文对易筋经做一次初步的剖析。
首先我需要回答这样一个问题:为什么你的交易程序需要一个新型的数据库?这是因为,当前市面上主流的数据库,不管是SQL还是NoSQL,第一优先的核心功能是查询,他们需要解决的,是在海量数据中快速定位到你真正需要的那一条,所以在设计上,如何快速定位就成了数据结构的重点。以 Redis 为例,它更像是一个巨大的哈希表,这导致在内存分配上注定了相邻数据不会存在连续内存区域,访问和写入数据都存在一定的开销。
而在金融实时交易场景下,以最快的速度处理当前最新的行情或是成交数据,才是第一优先需要考虑的,如果你同时需要保存这些数据,那么传统数据库那些难以割舍的写入耗时就会让你泪流满面。土法炼钢众会说,那我多开几个线程,用专门的线程来负责存储不就行了吗?这样看似在功能上实现了数据保存,但是系统内因此产生的诸多内存拷贝、网络冗余请求都会在不知不觉中加重你的延迟,并且臃肿的架构也会让你在数据种类增多时难以维护。
因此,一个可用来快速处理时间序列类型数据,并且保证存储的数据库产品就十分必需,这正是易筋经的定位目标。同时,如前文所述,由于使用了 mmap 做为底层存储机制,易筋经还同时肩负起了进程间通信的功能,使你不再需要一个诸如 ZeroMQ 或是 Redis 这样的消息队列中间件,一举两得。
我注意到有些朋友难以理解 mmap 对于性能提升的意义。这个问题的确在概念上有一些含糊之处,所以特别先做说明。原则上 mmap 并不会提升你访问内存的速度,共享内存名为最快的 IPC 机制,但我们也可以使用其他的方式(shmget(2) - Linux manual page)来创建共享内存,并不是非得以 mmap 形式;但你要理解 mmap 本质上是通过操作系统 kernel 后台进程异步完成内存内容到磁盘文件的同步操作,意味着它赋予你了一种在操作内存同时以零延时来操作磁盘文件的能力,使得你无需担心数据持久化方面的耗时,帮助我们同时完成通信和存储这两个重要任务,这是使用 mmap 方法的精髓所在。
下面介绍易筋经的设计方案。
首先我们为每个需要写数据的角色规定好属于他自己的一个写入单元(Journal),我们规定一个 Journal 只能有一个写入线程,从而保障它的进程/线程安全。写入者 Writer 在写入内容时,每一次都是通过一个原子操作在 Journal 中形成一个 Frame。Frame 结构包含一个头部(Header)信息和数据部分,Header 中定义跟该次写入有关的一些元信息,例如写入时间,数据类型等。数据部分的格式由数据类型定义,访问者利用元信息中的数据类型即可调用对应的解码器。这样,每一个 Journal 都可以看成由无数相邻 Frame 所组成的流式数据链。但是由于底层使用 mmap 进行磁盘回写,而 mmap 本身只能创建定长文件,所以我们定义每次 mmap 创建的文件为 Journal 的一个页(Page),结构如下:

每个 Page 是一个定长的文件(目前在功夫中我们定义为 128MB 大小),易筋经会根据使用者需要进行拼接,使得访问者透明的得到一个无限长(当然,真正的容量上限取决于磁盘大小)的 Journal:

在每次读写进行到 Page 边界的时候,易筋经需要小心进行一系列细节操作,使得访问者可以无缝的切换到下一个 Page,涉及到诸如调用 mmap 创建新的内存映射文件,对内存映射文件进行预处理等,这些操作往往相当耗时(毫秒级别),我们无法在实时读写数据时承受这个负担。易筋经的解决方案,是在后台启动并维护一个 PageEngine 进程,该进程负责提前载入缓存一些备用 Page,在需要时便可以立刻交付使用。在这种结构设计下,由于我们是夸进程的申请、分配、释放资源,所以需要多做一些安保工作,确保资源不会泄漏。PageEngine 内部会小心的记录申请者的进程编号 pid ,定期查询客户进程是否仍然健康存在,发现僵尸进程则会对其申请的资源进行释放操作。
至此,易筋经就具备了基础的数据读写能力。我们限定每个 Journal 只能有一个写入线程,但是可以有任意多个读取线程。一般而言每个写入线程都对应了一种特定的应用,例如行情接收,交易下单等。对于应用层的策略程序来说,往往需要关注多个 Journal,例如你很可能需要同时根据最新的行情和上一次的委托回报来决定下一次操作是追单还是撤单。为了支持这种需求,易筋经提供了一个特殊的 Journal Reader API,可以透明的把多个独立的 Journal 合并成一个虚拟的单独 Journal,使得在这个合并 Journal 中可以读取到各种不同 Writer 写入的数据:
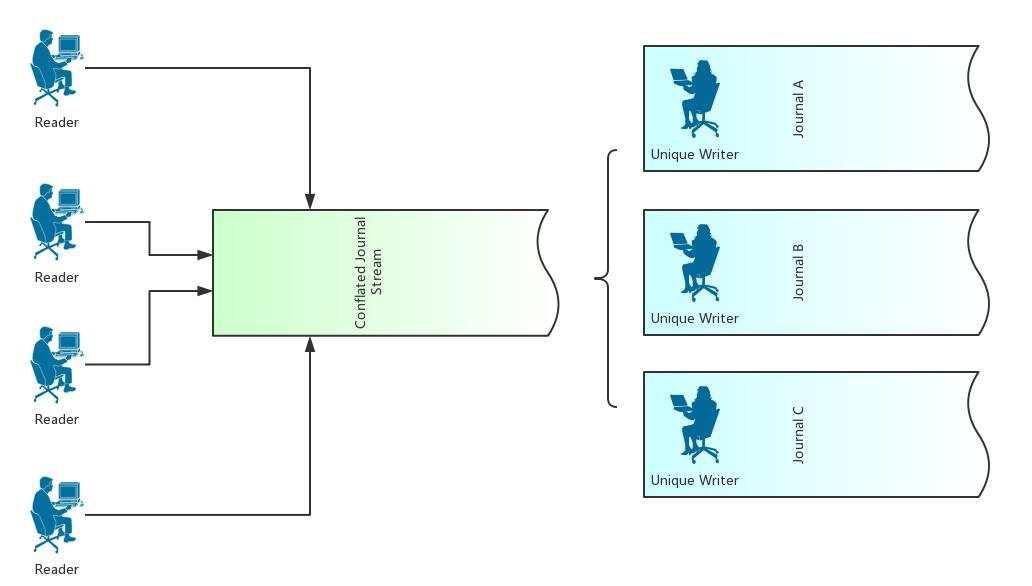
如上,我们就拥有了一整套支持极速读写时间序列流式数据,保证零延时存储,且支持最低延迟跨进程通信的解决方案,这就是易筋经的基础架构。需要注意的是,这个相当简洁的设计,在实现上仍有相当多的细节需要打磨,我们希望以开源的形式接受更广泛的审核和检验,来确保易筋经最终是一个工业级的数据库产品。
除了上述特性外,需要强调的是,当共享内存通信和实时存储这两个特点完美结合到一起的时候,实际上还根本的改变了整个系统数据处理的方式。我们知道典型的交易应用里数据流动的形态是,柜台 API 从网络接受数据,分发至策略线程进行运算处理,产生交易信号后调用柜台 API 发送下单指令,在这个模式下,系统的输入是 API 回调,输出是 API 调用,所有的中间状态都是通过临时变量的形式记录在内存里。这决定了系统运行必需依赖于外部系统(柜台)的开通和运行,并且内部状态的变更并不透明,例如你很难简单的获得系统内记录的委托单状态,除非修改程序增加暴露状态的功能。
在使用易筋经架构的情况下,我们事实上改变了系统的数据流动模式。系统的输入和输出,都变成了同时持久到磁盘的 Journal ,你会发现正像是它的名字所代表的那个神奇的武学秘籍一样,它突然赋予了你无数新的能力,例如:
- 获取委托单状态,无需修改交易程序,只需单独编写一个程序读取交易 Journal,里面含有所有委托请求和回报信息;
- 实时延迟计算,利用合并过的行情(MD)和交易(TD)Journal ,你可以直接获得触发委托的行情和下单记录,利于 Frame Header 中记录的纳秒时间戳便可以计算出触发这次下单的策略代码运行时间,同样的,这个功能可以在不修改、影响交易程序的情况下单独开发;
- 盘后回放,根据行情和交易记录,你可以在盘后重新运行策略程序,由于程序拥有同样的输入和运算逻辑,一定可以得到同样的输出,因为此时并非实盘交易,你便可以修改策略程序,增加不影响输出的打印语句,帮助你更好的分析和理解策略运行状态;
目前易筋经的缺点在于缺乏快速查询和分析工具,每次使用易筋经访问历史数据都必须进行顺序读取,并且没有高级查询语言来进行结构化的分析工作,在这方面我们已经有了很好的思路,并计划在未来不久推出易筋经专用的查询分析工具,也欢迎大家提供建议。
如果你还在使用 MySQL、MongoDB 等传统型数据存储交易数据,或是使用Protobuf、ZeroMQ 等“低速”的通信方式,希望你在看完本文后会对易筋经有那么一点点心动。我们希望易筋经可以成长为一个通用的,经过广泛生产环境考验的工业级产品,因此欢迎大家对它做各种脑洞出奇的实验和使用。
Reprinted from 知乎,the copyright all reserved by the original author.
Disclaimer: The content above represents only the views of the author or guest. It does not represent any views or positions of FOLLOWME and does not mean that FOLLOWME agrees with its statement or description, nor does it constitute any investment advice. For all actions taken by visitors based on information provided by the FOLLOWME community, the community does not assume any form of liability unless otherwise expressly promised in writing.
FOLLOWME Trading Community Website: https://www.followme.com


Hot
No comment on record. Start new comment.